


厂商:
备案号:
开源阅读app下载安装官方最新版阅读的板块超级的齐全,每天可以在线选择阅读的书籍很多,书籍阅读记录云同步,连载书籍章节极速更新,各种精彩的章节全部都能够获取,还有很多小说的番外也能在平台阅读,很多隐藏彩蛋都有解读,无论是男女生都可以在这找到适合自己阅读的书籍,
开源阅读怎么添加书源
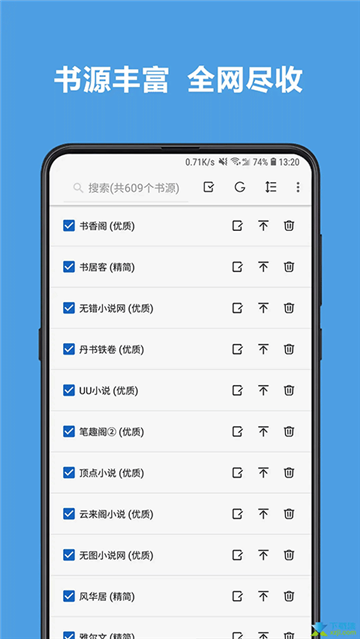
书源:https://raw.githubusercontents.com/mzbgf/tangguo/master/exportBookSource.json
在本站下载打开软件,点击我的,进入书源管理界面;

点击右上角的三个点,选择网络导入;

将上面的书源粘贴复制到软件界面中,点击确定;

即可看到以下所有书源,你可以自行挑选进行导入;

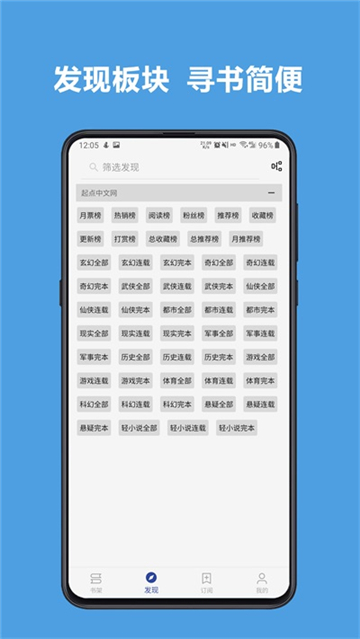
之后在发现就可以看到各网站的资源啦。

软件介绍:
导入本地书籍文件,支持TXT、EPUB、RAZ及ZIP等多种格式;
多种阅读主题、夜间模式、翻页效果随意切换;
成语来源于历史故事、寓言故事、神话故事等,包含了政治、经济、文化等多方面知识。通过成语故事,少年儿童可以了解中华民族悠久的历史、宝贵的文化遗产和智慧的结晶。
赶紧来试试吧~
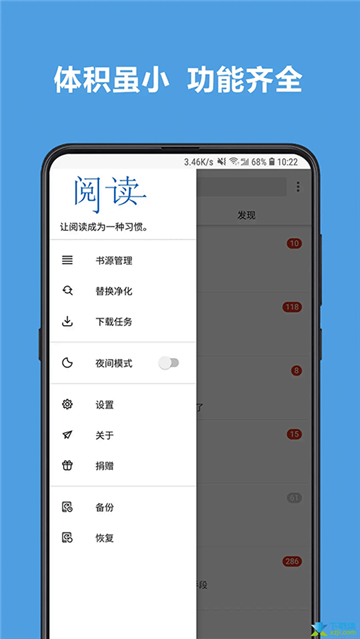
软件特色:
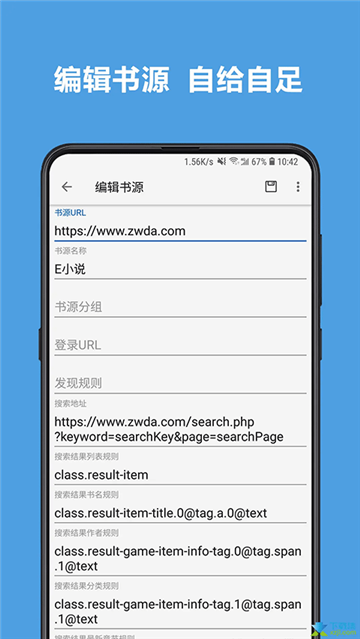
-自定义书源,自己设置规则,抓取网页数据,规则简单易懂,软件内有规则说明。
-列表书架,网格书架自由切换。
-书源规则支持搜索及发现,所有找书看书功能全部自定义,找书更方便。
-支持替换净化,去除广告替换内容很方便。
-支持本地TXT、EPUB阅读,手动浏览,智能扫描。
-支持高度自定义阅读界面,切换字体、颜色、背景、行距、段距、加粗、简繁转换等。
-支持多种翻页模式,覆盖、仿真、滑动、滚动等。
-软件开源,持续优化,无广告。
软件优势:
1、个性化推荐
海量内容,懂你的书旗为你推荐喜爱的书籍,再无书荒烦恼
2、云书架
书籍阅读记录云同步,连载书籍章节极速更新,还有多套惊艳的书架皮肤任你选择
3、阅读体验细致
精致排版、护眼模式、极简模式、亮度自适应、多样独特的阅读页主题,每一个阅读姿势都舒服
4、变身原创作者
如果您想写小说!请来我们的签约平台!这里有一个梦想的舞台!想写就写!要写的闪亮

软件亮点:
1、开源阅读能够支持各种不同文章等记录,保证用户能够随时进行获取阅读;
2、软件之中各种不同的备份软件等记录非常清晰,能够随时获得阅读的清晰流程;
3、定义的自己的规则,能够进行网页数据的记录,找到自己喜欢的书进行阅读。
软件说明:
书源规则说明:
・ 书源规则基于 HTML 标记,如class、id、tag等
・ 想要写规则先要打开网页源代码,在里面找到想要获取内容对应的标签
・ Chrome 可以在网页上右击点击检查可以方便的查看标签
书源规则写法:
・ @为分隔符,用来分隔获取规则
・ 每段规则可分为3段
・ 第一段是类型,如class、id、tag、text、children等,children获取所有子标签,不需要第二段和第三段,text可以根据文本内容获取
・ 第二段是名称,text,第二段为文本内容的一部分
・ 第三段是位置,class、tag、id等会获取到多个,所以要加位置
・ 如不加位置会获取所有
・ 位置正数从0开始,0是第一个,如为负数则是取倒数的值,-1为最倒数第一个,-2为倒数第二个
・ !是排除,有些位置不符合需要排除用!,后面的序号用:隔开0是第1个,负数为倒数序号,-1最后一个,-2倒数第2个,依次
・ 获取列表的最前面加上负号- 可以使列表倒置,有些网站目录列表是倒的,前面加个负号可变为正的
・ @的最后一段为获取内容,如 text、textNodes、href、src、html 等
・ 如果有不同网页的规则可以用 || 或 && 分隔 或 %%
・ ||会以第一个取到值的为准,
・ && 会合并所有规则取到的值,
・ %% 会依次取数,如三个列表,先取列表1的第一个,再取列表2的第一个,再取列表3的第一个,再取列表1的第2个.......
・ 如需要正则替换在最后加上 ##正则表达式##替换为,##替换最新版本支持所有规则
・ 例:class.odd.0@tag.a.0@text|tag.dd.0@tag.h1@text#全文阅读
・ 例:class.odd.0@tag.a.0@text&tag.dd.0@tag.h1@text#全文阅读
 首页
首页
 安卓游戏
安卓游戏
 安卓软件
安卓软件
 热门专题
热门专题
 更多
更多










